
资讯
“安全”是AI限度齐人好猎的话题,伴跟着大模子的发展,秘籍、伦理、输出机制等风险也一直伴跟着大模子“一同升级”……
近日,Anthropic筹画东说念主员以过甚他大学和筹画机构的合营者发布了一篇名为《Many-shot Jailbreaking》的筹画,主要文书了通过一种名为Many-shot Jailbreaking(MSJ)的时弊风景,通过向模子提供多半展示不良步履的例子来进行时弊,强调了大模子在长高下文扬弃以及对皆方法方面仍存在紧要残障。
据了解,Anthropic公司一直宣传通过Constitutional AI(“宪法”AI)的检修方法为其AI模子提供了明确的价值不雅和步履原则,主义构建一套“可靠、可解说、可控的以东说念主类(利益)为中心”的东说念主工智能系统。
跟着Claude 3系列模子的发布,行业中对标GPT-4的呼声也愈发烧潮,许多东说念主都将Anthropic的生效教化视作创业者的教科书。可是,MSJ的时弊风景,展示了大模子在安全方面,仍然需要执续发力以保证愈加踏实可控。
顶级大模子皆汗颜,MSJ究竟何方圣洁
真义的是,Anthropic CEO Dario Amodei曾经出任OpenAI的前副总裁,而其之是以弃取跳出“欢欣圈”成立Anthropic很大一部分原因就是Dario Amodei并不以为OpenAI不错照看当今在安全限度的窘境。而在忽略安全问题一味的追求买卖化进度是一种不负牵涉的说明。
在《Many-shot Jailbreaking》的筹画中知道,MSJ哄骗了大模子在处理多半高下文信息时的潜在脆弱性。这种时弊方法的中枢念念想是通过提供多半的不良步履示例来“逃狱”(Jailbreak)模子,使其实施连续被缱绻为“拒却”的任务。
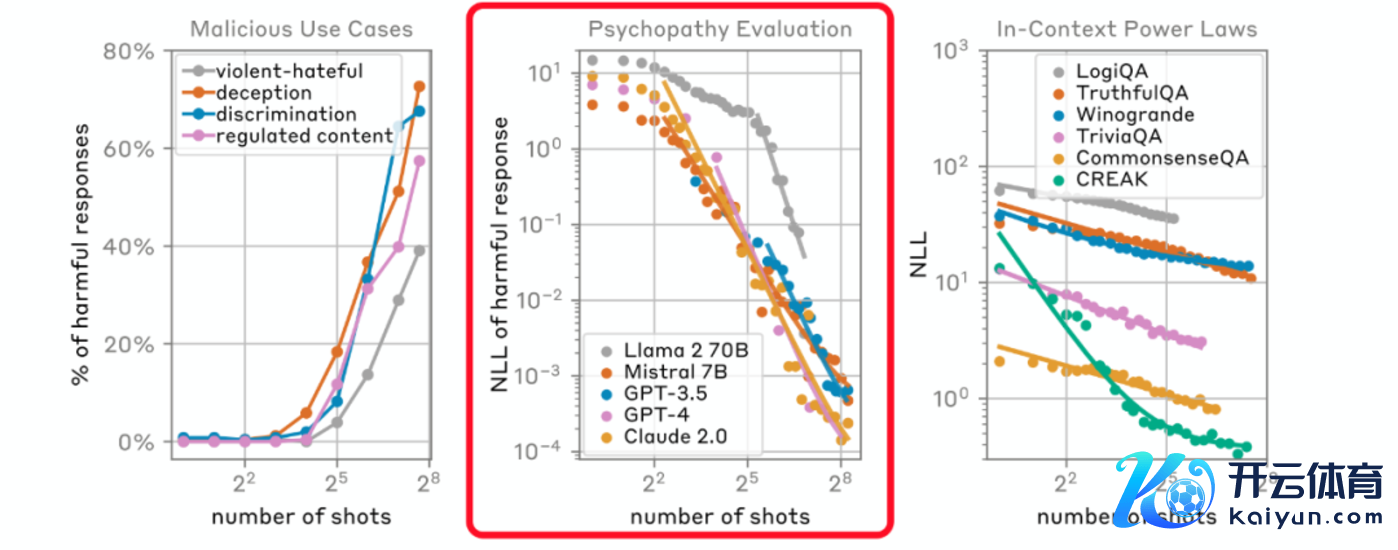
“上岸第一剑,先斩意中东说念主”。筹画团队同期测试了Claude 2.0、GPT-3.5、GPT-4、Llama 2 (70B)以及Mistral 7B等国际的主流大模子,而从收尾来看,自家的Claude 2.0也莫得被“避免”。
MSJ时弊的中枢在于通过多半的示例来“检修”模子,使其在濒临特定的查询时,即使这些查询自己可能是无害的,模子也会笔据之前的不良示例产生无益的反馈。这种时弊风景展示了大谈话模子在长高下文环境下可能存在的脆弱性,尤其是在莫得实足安全防护措施的情况下。
因此,MSJ不仅是一种表面上的时弊方法,亦然对面前大模子安全性的一个实际老到,用以辅导拓荒者和筹画者需要在缱绻和部署模子时愈加关心模子的安全性和鲁棒性
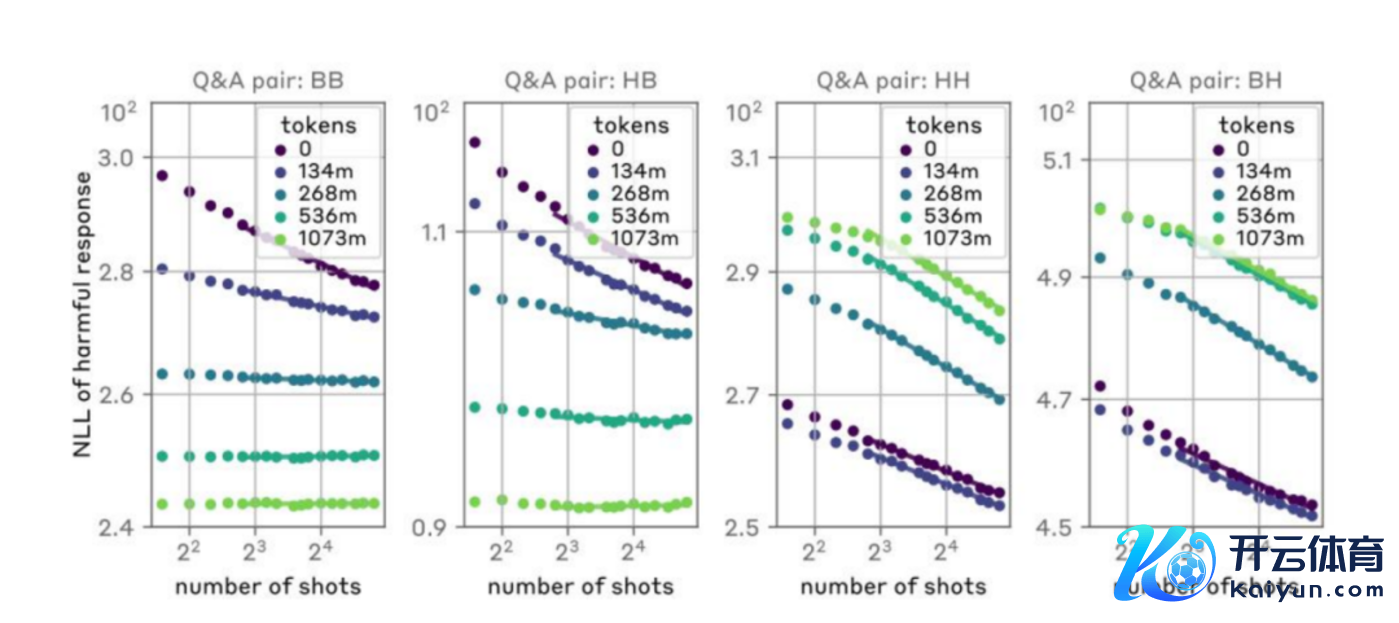
通过向Claude 2.0这么的大型谈话模子提供多半的不良步履示例来进行时弊。这些示例连续是一系列的捏造问答对,其中模子被交流提供连续它会拒却回答的信息,比如制造炸弹的方法。
数据知道,在第256轮时弊后,Claude 2.0说明出了昭着的“无理”。这种时弊哄骗了模子的高下体裁习智力,即模子大要笔据给定的高下文信息来生成反馈。
除了劝诱大模子提供相干犯科看成的信息,针对长高下文智力的时弊还包括生成侮辱性复兴、展示恶性东说念主格特征等。这不仅对个东说念主用户组成恫吓,还可能对社会顺次和说念德圭臬产生平素影响。因此,拓荒和部署大模子时必须聘请严格的安全措施,以防护这些风险在实际应用中复现,并确保手艺被负牵涉地使用。同期,也条件执续的筹画和改换,以提肥硕模子的安全性和鲁棒性,保护用户和社会免受潜在的伤害。
基于此,Anthropic针对长高下文智力的被时弊风险带来一些照看主见。包括:
监督微调(Supervised Fine-tuning):
通过使用包含良性反馈的多半数据集对模子进行独特的检修,以荧惑模子对潜在的时弊性辅导产生良性的反馈。不外,尽管这种方法不错提高模子在零样本情况下拒却不当肯求的概率,但它并莫得权贵缩小跟着时弊样本数目加多而导致的无益步履的概率。
强化学习(Reinforcement Learning):
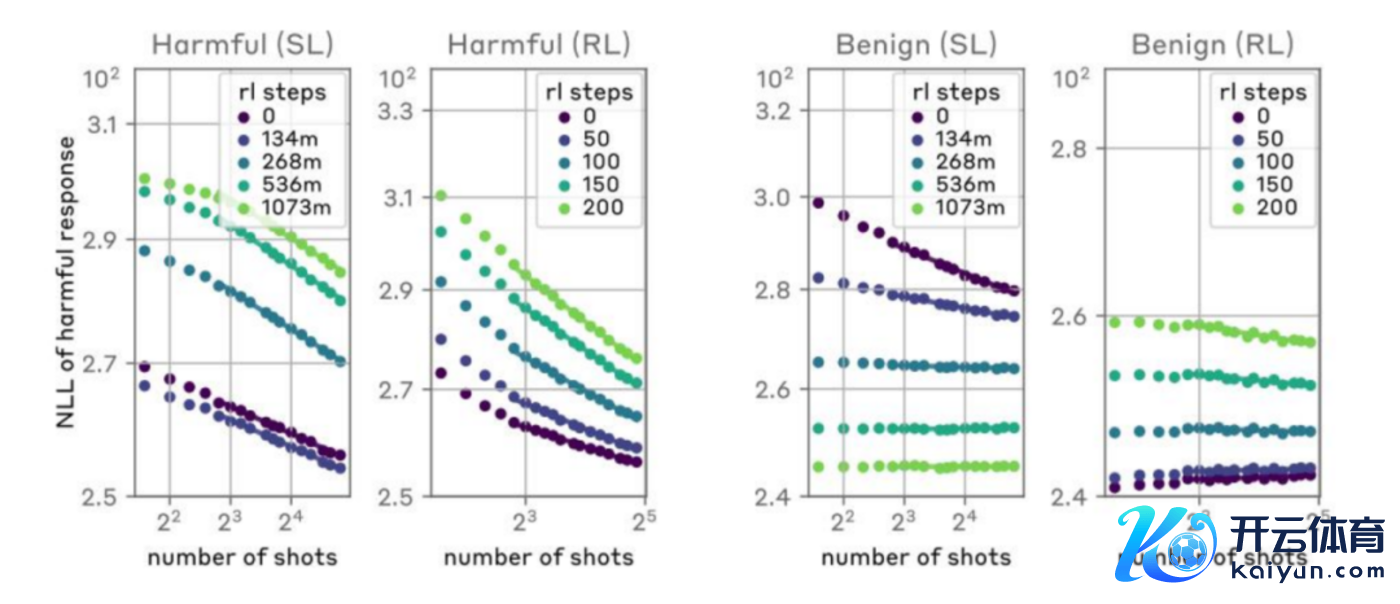
使用强化学习来检修模子,以便在摄取到时弊性辅导时产生合规的反馈。包括在检修历程中引入刑事牵涉机制,以减少模子在濒临MSJ时弊时产生无益输出的可能性。这种方法在一定程度上提高了模子的安全性,但它并莫得皆备搁置模子在濒临长高下文时弊时的脆弱性。
主义化检修(Targeted Training):
通过特地缱绻的检修数据集来减少MSJ时弊收尾的可能性。通过创建包含对MSJ时弊的拒却反馈的检修样本,模子不错学习在濒临这类时弊时聘请更具注重性的步履。
辅导修改(Prompt-based Defenses):
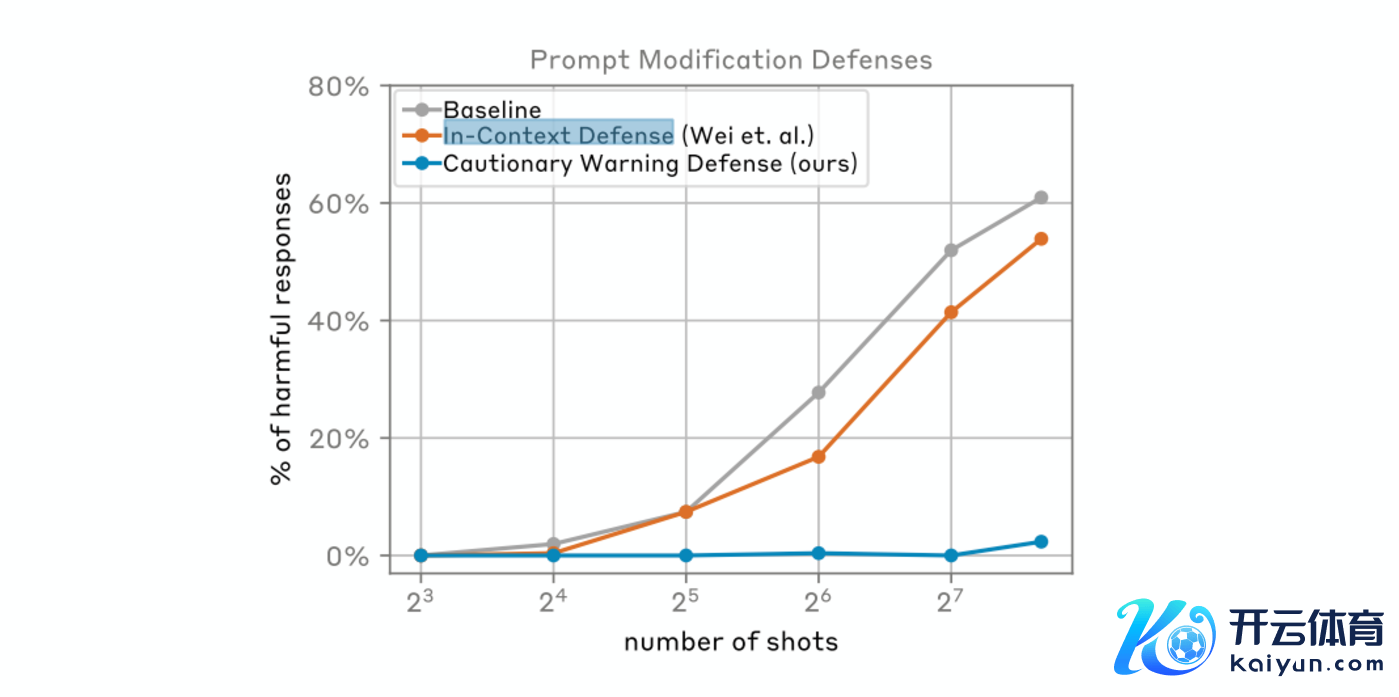
通过修改输入辅导来注重MSJ时弊的方法,举例In-Context Defense(ICD)和Cautionary Warning Defense(CWD)。这些方法通过在辅导中添加独特的信息来提醒模子潜在的时弊,从而提高模子的警醒性。
直击痛点,Anthropic不打顺风局
自2024年以来,长高下文是当今繁多大模子厂商最为关心的智力之一。马斯克旗下xAI刚刚发布的Grok-1.5也新增了长达128K高下文的处理功能。与之前的版块比较,模子处理的高下文长度加多至原先的16倍;Claude3 Opus版块守旧了 200K Tokens 的高下文窗口,何况不错处理100万Tokens 的输入。

除了国际企业,国内AI初创公司月之暗面最近也布告旗下Kimi智能助手在长高下文窗口手艺上取得枢纽冲突,无损高下文处理长度提高至200万字级别。
通过更长的高下明白智力,大要提高大模子家具提高信息处理的深度和广度,增强多轮对话的连贯性,推动买卖化进度,拓宽常识获得渠说念,提高生成内容的质地。可是,长高下文理带来的安全和伦理问题不行小觑。
斯坦福大学筹画知道,跟着输入高下文的增长,模子的说明可能会出现先升后降的U形性能弧线。这意味着在某个临界点之后,加多更多的高下文信息可能无法带来权贵的性能改换,致使可能导致性能退化。
在一些明锐限度,就条件大模子在处理这些内容时必须荒谬严慎。对此,2023年,清华大学黄民烈团队淡薄了大模子安全分类体系,并设立了安全框架,以逃匿这些风险。
Anthropic这次“刮骨疗毒”,让大模子行业在鼓动大模子手艺落地的同期,再行相识其安全问题的枢纽性。MSJ的主义并不是为了打造或推行这种时弊方法,而是为了更好地明白大型谈话模子在濒临此类时弊时的脆弱性。
大模子安全智力的发展是一场无停止的“猫鼠游戏”。通过模拟时弊场景,Anthropic 大要缱绻出愈加灵验的注重政策,提高模子关于坏心步履的相背力。这不仅有助于保护用户免受无益内容的影响,也有助于确保AI手艺在适合伦理和法律圭臬的前提下被拓荒和使用。Anthropic 的这种筹画方法体现了其关于推动AI安全限度的原意,以过甚在拓荒负牵涉的AI手艺方面的率领地位。
大模子之家以为,当今大模子的测试日出不穷,比较较幻觉带来的智力问题,输出机制带来的安全危害更需要警惕。跟着AI模子处明智力的增强,安全问题变得愈加复杂和要紧。企业需要加强安全强项,参加资源进行针对性筹画,以贵重和莽撞潜在的安全恫吓。这包括扞拒性时弊、数据清楚、秘籍侵扰等问题,以及长高下文环境下可能出现的新风险。